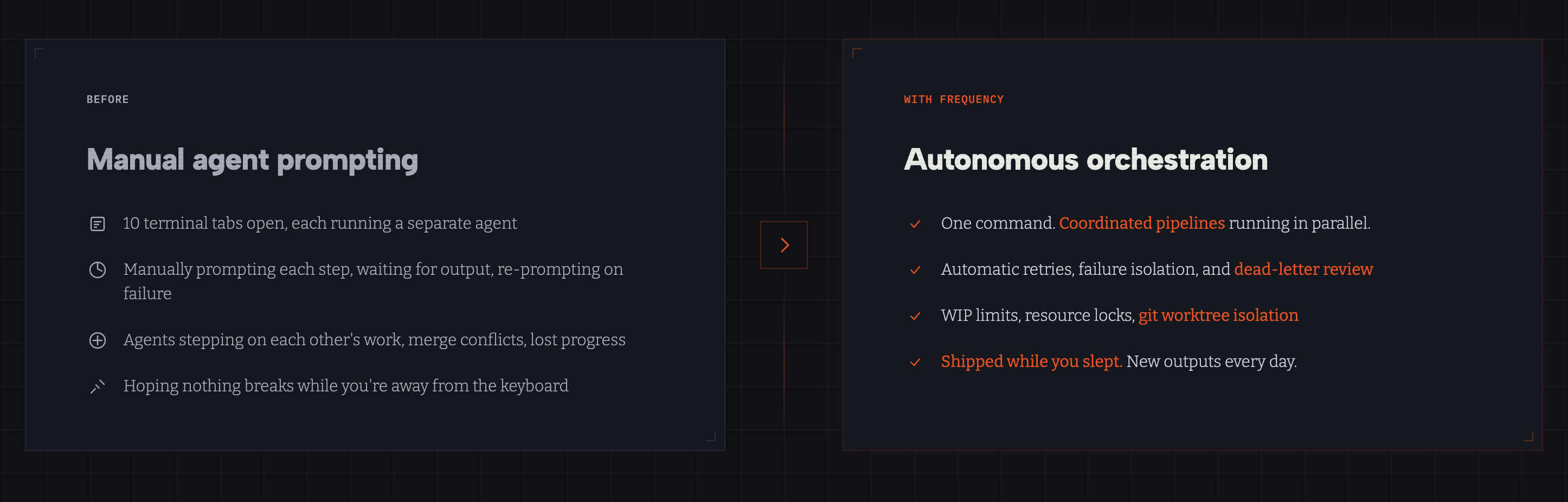
The first autonomous end-to-end software factory

10 agent pipelines. 30 production apps. Zero lines of application code. Runs 24/7 (as long as we have the tokens).
The first month of running our agent orchestration system was equal parts breakthrough and putting out fires. We shipped 30 production apps at Cashew Crate without writing a line of application code. We also burned through API rate limits in hours and accumulated hundreds of stale git worktrees.
This is a technical accounting of building Frequency: what the architecture looks like, what worked, what broke, and what to do differently going forward.
The problem that forced us to build this
We started by running Claude Code and Codex on individual tasks. Generate an app idea > implement > deploy. Each step worked fine in isolation but problems with agent orchestration surfaced when they were strung together.
Step 3 would start before step 2 finished or a failure in review would leave the subject stuck with no recovery path. Running multiple of these sequences in parallel on the same repo meant constant merge conflicts and state corruption. Bash scripts couldn't help since they don't have retry semantics, dependency resolution, or any concept of work-in-progress limits.
We compared existing options. Temporal, Airflow, Conductor etc. are general-purpose workflow engines built for microservice orchestration with task queues and workers. Which was too much infrastructure for what we needed. Agent wrappers like Auto-Claude and Antfarm help you run one agent well, but none of them coordinate multiple workflows with each other.
We needed cross-pipeline coordination and couldn't find it anywhere. So we built Frequency to help us with this.
The architecture
Frequency is config-driven agent orchestration. You define workflows as YAML state machines with each workflow having subjects, states, transitions, and steps. The runtime discovers subjects (units of work, apps in our case) and advances them through states and handles retries. The steps can be anything you can do on a computer: LLM calls, shell commands, git operations, API calls.
Here's the basic shape of a pipeline config:
factory_id: build
state:
initial: selected
terminal: [promoted, failed]
steps:
- id: implement
from_states: [selected]
to_state: implemented
- id: review
from_states: [implemented]
to_state: ready_for_build
- id: build_validate
from_states: [ready_for_build]
to_state: built
- id: promote
from_states: [built]
to_state: promotedEach step can invoke an agent or a shell command. Agent steps are for work that requires judgement (implementation, review). Shell steps handle everything deterministic (validation, deployment). The runtime figures out what to run based on a subject's current state, evaluates any prerequisites, and advances the subject forward or handles the failure.
State is file-backed and lives in the repo without the need for databases or message queues. We wanted zero infrastructure dependencies beyond the filesystem. You can inspect everything with git log.

Concurrency control
This was necessary because agents writing to the same repo in parallel will corrupt each other's work without serialisation.
We learned this the hard way. Early on we had no concurrency controls and the build pipeline would accept 15 subjects simultaneously where every agent would conflict with every other agent on shared files.
Frequency now handles concurrency at multiple levels:
- capping parallel execution globally and per-step
- limiting how many subjects can sit in a given state at once (WIP limits)
- named resource locks that prevent specific conflicts like two agents pushing to the same branch simultaneously.
The resource locks have stale detection built in so that a crashed worker doesn't permanently block a pipeline. Getting the TTL values right for each resource type took trial and error. Some locks need to be held for minutes, others for hours, and the consequences of getting it wrong are different in each case.
Cross-pipeline coordination
This was the hardest part to get right and the thing we couldn't find in any existing tool.
We run 10 pipelines including build, deploy, marketing etc. which all talk to each other. The release pipeline needs to batch promoted builds before deploying shared infrastructure.
Frequency solves this with declarative predicates. A pipeline step can declare requirements that must be true before it runs. The simplest example: the deploy pipeline won't pick up an app until the build pipeline marks it as ready. The coordinator evaluates these predicates at plan time and only schedules work when all requirements are satisfied.
# Deploy waits for build to finish
requires:
- type: subject_state
factory_id: build
subject: "{subject}"
states: [promoted]We also have predicates that gate on capacity. Our ideas pipeline checks how many apps are already queued for build and stops generating new ones if the queue is full. This prevents upstream pipelines from flooding downstream ones. Capacity gating is something we underestimated initially and it ended up being one of the most useful coordination mechanisms we have.
The key insight was making coordination declarative rather than imperative. Our early attempts used callbacks and polling scripts. Each pipeline would check the state of other pipelines in its own step logic, which meant coordination was scattered across dozens of scripts. Moving it into the config made it testable and much easier to reason about when debugging why a subject was stuck.
Worktree isolation
Every agent call that modifies code runs in an isolated git worktree. The agent gets its own branch and can write and commit freely without affecting the main branch or interfering with other agents running in parallel. Changes are merged back after the step succeeds. If the merge fails, there's a fallback strategy.
This sounds straightforward but the edge cases were painful. Worktree operations need to be serialised to prevent git internal lock contention. Stale worktrees accumulate when steps fail mid-operation. A step that times out at 40 minutes can leave a worktree with uncommitted changes that blocks future runs. We've built cleanup routines but edge cases keep appearing.
The 40/60 split
One of the more useful lessons from production was having roughly 40% of our pipeline steps as agent calls, and 60% as deterministic scripts. Using an agent where a bash script would work is more expensive and less reliable.
We use agents at steps where judgement is needed e.g., marketing copy, SEO etc. We use shell commands and Python scripts for everything else e.g., deployment, validation etc.
Build validation is a bash script that checks for out/index.html, CSS files, JS chunks, and deploy is a Python script. None of these need an LLM.
The agent calls are where non-determinism lives. The same step on the same input can succeed or fail depending on context window, model load, or prompt sensitivity. Our entire retry and dead-letter system exists because of this.
Failure handling
Every step in Frequency has a failure classification: retryable or terminal. Retryable failures go back into the queue with backoff and get picked up on the next cycle. Terminal failures go to a dead-letter queue for manual review.
The dead-letter queue is an append-only audit trail. Each entry captures what failed with reasoning and the tail end of the output. From the dashboard you can inspect the failure root cause and then either requeue the subject or fix the systemic issue.
We use backoff values between 15 and 90 seconds depending on the step. Agent calls get longer backoff since they're more likely to fail from transient issues (model load, rate limits). Git operations get shorter backoff since they typically either work immediately or need manual intervention.
Getting the failure classification right took iteration. Some failures look retryable but are actually terminal (the agent keeps making the same mistake). Some look terminal but are actually transient (API rate limit that clears in 60 seconds). We ended up adding inference so the runtime can make reasonable defaults when a step doesn't explicitly declare its classification.
What broke
Merge conflicts at scale since early on we had no WIP limits. The build pipeline would accept 15 subjects simultaneously and every agent would conflict with every other agent on shared files. Now we cap concurrent implementations at 3 and use a resource lock for any step that touches shared code.
Stale worktrees accumulating. When agent steps fail mid-operation, the worktree doesn't always get cleaned up. We added cleanup routines, but edge cases keep appearing. A step that times out at 40 minutes can leave a worktree with uncommitted changes that blocks future runs. Our cleanup now checks for worktrees older than their step's timeout plus a buffer.
Agent output variance. The same implementation prompt on the same subject produces different results across runs. Sometimes the agent generates a complete app but sometimes it generates scaffolding and stops. Our review step catches most of these, but the variance means we can't predict throughput precisely. On a good run, 4 out of 5 subjects pass through on the first attempt. On a bad run it's closer to 2 out of 5.
Token limits as the real ceiling. The system can ideate, implement, build, deploy, and market 3-5 apps per hour. But we hit session rate limits fast and get throttled. But the positive takeaway is that the throughput ceiling is the token budget rather than the orchestration itself. We've optimised by pushing 60% of steps to deterministic scripts, but the agent-heavy stages are expensive. As token costs drop and context windows grow, the throughput ceiling lifts automatically. We built Frequency so that when agents get cheaper and faster, the system scales with them without any rearchitecting.
The greedy scheduler
A small detail that made a meaningful difference. Our run loop is greedy, if any subject succeeded in the last cycle, the runner loops immediately without sleeping. It only sleeps when the work queue is empty.
During active periods, subjects advance through states as fast as the agents can execute. During quiet periods, the runner polls at 15-45 seconds depending on the pipeline. This means we don't waste time sleeping between steps if there are tasks pending.
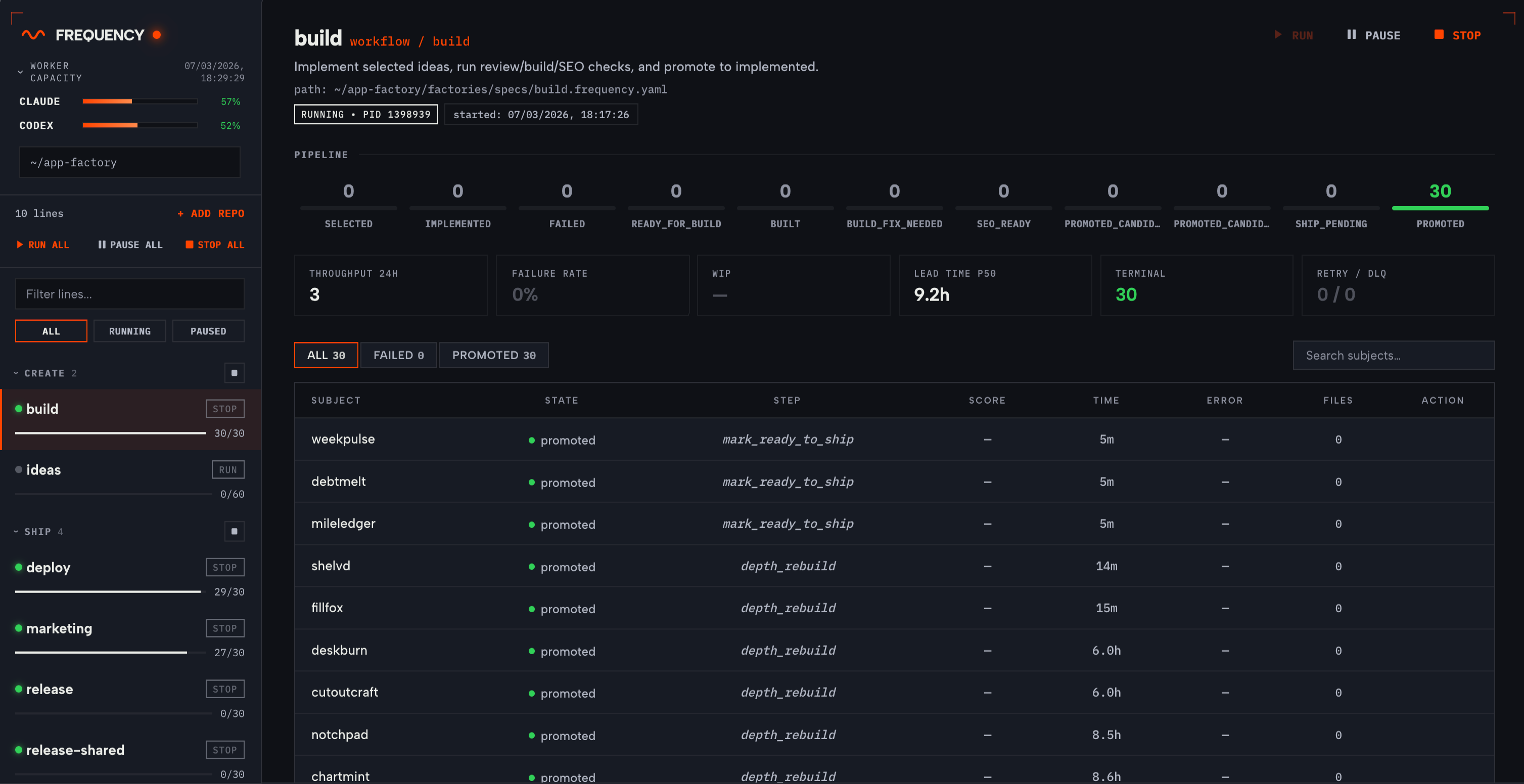
The control centre
Frequency runs alongside a dashboard built as a single-page app. This gives us a good overview of real-time status per pipeline, logs per step, failure root causes, and fine-grained controls. You can manually transition subjects between states, requeue from dead-letter, pause individual pipelines, and adjust autonomy levels.
For our 10-pipeline setup, we check the dashboard once a day. Luckily on most days there's nothing to intervene on (given we have the token budget to allocate to it), but when something fails, we have an agent running that finds why the error's happening and surfaces it to us. 9/10 times, we just click a button saying "Fix" and it just works.
What we're still figuring out
Agent quality at scale is an unsolved problem. When Claude writes an app and then reviews it, the review can be tautological. We're experimenting with using different models for implementation vs. review (Claude for implementation, Codex for review) to reduce this.
The generated config can get verbose for complex workflows. Our release-shared pipeline has 10 steps with delta predicates and conditional environment checks with multiple integration points. We're exploring a higher-level DSL but haven't committed to it yet.
Cost attribution per step is something we need. We know roughly what we're spending but we can't yet attribute cost to individual pipeline stages. This is on the roadmap.
We're also curious what patterns others are using for multi-agent coordination. Most of what we've seen focuses on making individual agent runs better. The multi-pipeline coordination problem feels underexplored.
What's next
We're opening Frequency to design partners. App development was our proving ground but the runtime is workflow-agnostic.
If you want agents building and running your workflows autonomously, safely and at scale, we'd love to give you early access at frequency.sh.
We plan to release deeper write-ups on specific aspects, including: our approach to agent reliability and how we handle cross-pipeline coordination at scale.