Introducing Frequency: agent orchestration that runs your workflows without you
Introducing Frequency. AI agent orchestration that autonomously defines and runs any repeatable workflow for you, continuously and at scale.
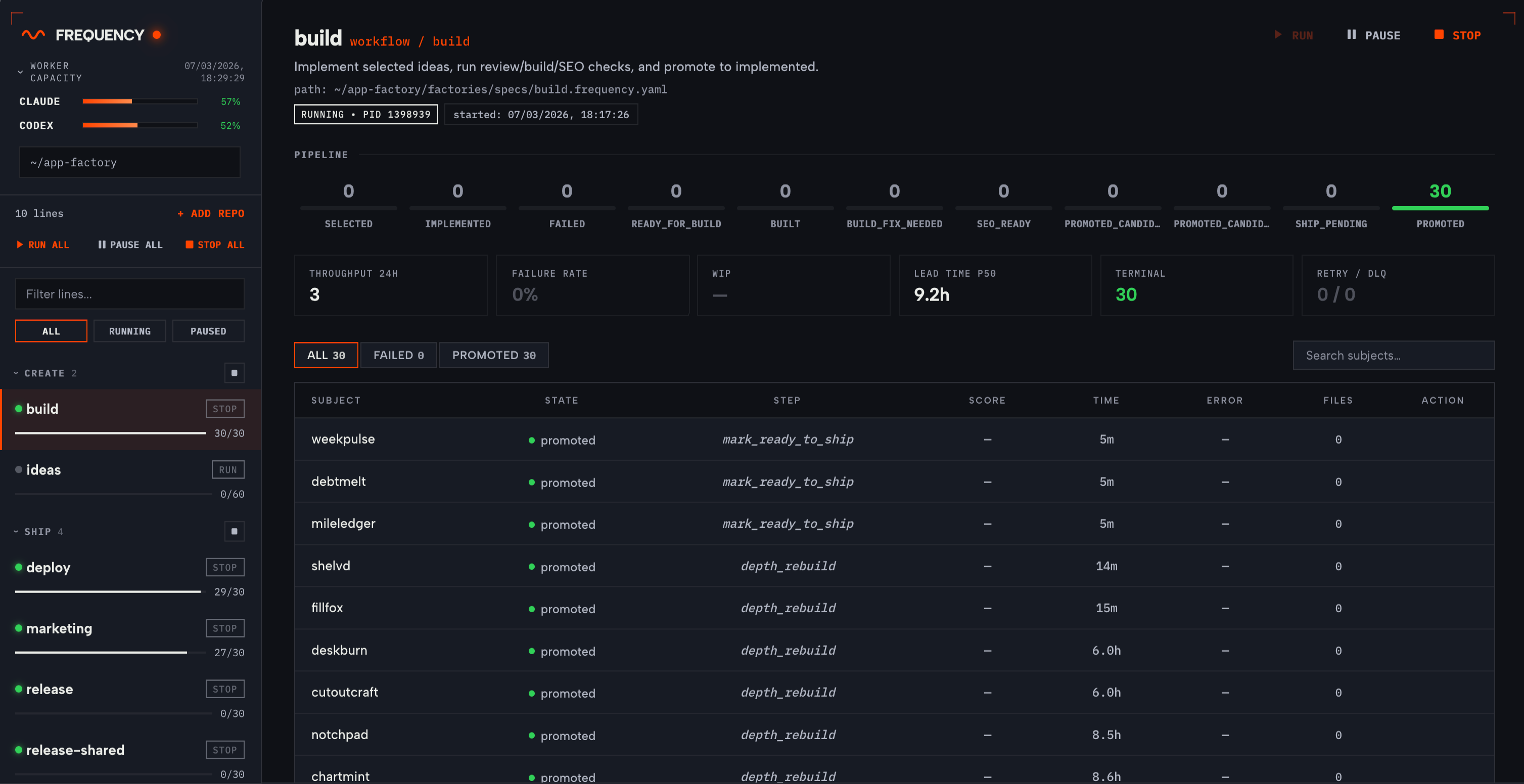
Frequency has rapidly shipped 30 production apps (and counting) at Cashew Crate from scratch, autonomously. These are real, fully functional apps with working payments, accounts, analytics, and marketing integrations. All we need to do is run Frequency and we see new apps appear everyday, without any prompting or babysitting.
We pointed Frequency at our app development codebase and it generated the workflow config and scripts, then ran them continuously. The agents autonomously:
- generated ideas
- validated them against user signals and needs
- decided what to build
- implemented the apps
- ran review and build checks
- fixed failures
- deployed successful builds
- triggered marketing
- processed bug reports from user feedback (using Bugjar, built on Frequency!)
All in a continuous loop across 10 parallel pipelines that are aware of each other. Marketing waits until deploy confirms a live endpoint. Bug fixes feed back through build and deploy. Each pipeline calls agents where judgement is needed, and deterministic scripts everywhere else. These workflows synchronise automatically through state predicates and shared resource locks. Additional agent pipelines can be added easily for any evolving use case.
Your repo already has patterns worth automating. Frequency analyses your codebase, generates the workflow config and scripts, and runs them safely across parallel pipelines. It also works many different domains: app development (our proving ground), content pipelines, data processing, release management, research, and more.

The problem we were solving
We were running agents (Claude Code, Codex) on individual tasks and getting decent results, but stringing multiple agent calls into a reliable pipeline was painful. Step 3 would run before step 2 finished. A failure in review would leave the subject stuck with no recovery path. Running 10 of these pipelines in parallel with shared repos meant constant merge conflicts and state corruption. We tried scripting it, but bash scripts don't have retry semantics, dependency resolution, or WIP limits.
What we built
Frequency is agent orchestration that analyses your codebase, generates workflow config as YAML state machines, and runs them. Each workflow has states, transitions, and steps. A step can be deterministic like a shell command or a git operation, or non-deterministic like an agent call. The runtime polls for subjects (units of work, in our repo it was apps), advances them through states, handles retries for transient failures, and dead-letters permanent failures for manual review.
The key design decisions:
- State is repo-local JSON files, no database or message queue. You can inspect everything with git log. We wanted the runtime to have zero infrastructure dependencies beyond the filesystem.
- Workflows coordinate through state predicates and shared resource locks. Our deploy pipeline waits for build to reach a specific state before picking up a subject. This is configured automatically, not coded in a script.
- Four levels of concurrency control: global max workers, per-step max workers, per-state WIP limits, and named resource locks. This was necessary because agents writing to the same repo in parallel will corrupt each other's work without serialisation.
- Agent calls run in git worktrees with integration gates. The agent works in an isolated branch, and the post-step operation merges back only if the step succeeds.
Frequency is agent-agnostic: it works with Claude Code, Codex, Cursor, or any CLI tool. A step is just a command the runtime executes. We use Claude for implementation and review, Codex for specific tasks, and shell scripts for everything deterministic. Swap agents without changing the workflow.
The control centre gives you full visibility and fine-grained control over every pipeline. Real-time status updates, logs per step, failure root causes, and the ability to manually transition subjects between states, requeue from dead-letter, or pause individual pipelines. If you're not comfortable letting agents run fully autonomously from day one, the dashboard lets you observe first, intervene when needed, and gradually increase autonomy as you build confidence.

What surprised us
Cross-pipeline coordination was the hardest part and the thing we couldn't find in existing tools. We run 10 pipelines (ideas, build, review, deploy, release, marketing, bugfix, depth, SEO, and a shared infrastructure sync). The marketing pipeline needs to know deploy succeeded. Bug fixes need to flow back through build and deploy. Getting this to work declaratively through state predicates rather than imperative callbacks took several iterations.
The other surprise was how much of the pipeline should not be agents. We use agents at steps where judgement is needed (implementation, review, triage) and deterministic scripts everywhere else (build validation, deployment, git operations). Roughly 40% agent calls, 60% shell commands. Throwing an agent at a step that should be a bash script is slower, more expensive, and less reliable.
What broke
Plenty. Some highlights:
- Early on we had no WIP limits, so the build pipeline would accept 15 subjects simultaneously and every agent would conflict with every other agent on shared files. Adding per-state WIP limits and resource locks fixed this but we lost a week of runs to it.
- Agent calls are nondeterministic, so the same step on the same input can succeed or fail depending on context window, model load, or prompt sensitivity. Our retry and dead-letter system exists because of this, not as a nice-to-have.
- Git worktree isolation solved merge conflicts but introduced its own failure mode: stale worktrees accumulating when steps fail mid-operation. We added cleanup routines but still hit edge cases.
- Token limits are our biggest operational constraint. The system can push 3-5 apps per hour through the full pipeline (ideate through deploy) but we burn through API rate limits fast and get throttled to roughly 3 before hitting the ceiling in each session. We've optimised by using deterministic scripts wherever possible (about 60% of steps don't need an agent at all) but the agent-heavy stages (implementation, review, triage) are expensive. The throughput ceiling is the token budget rather than the runtime.
Beyond app development
App development was our proving ground, but the runtime doesn't care what the workflow does. A workflow is states, transitions, and steps. The steps can be anything you can do on a computer: LLM calls, shell commands, git operations, API calls. We're already working on content pipelines, data processing workflows, and release management automation. If your team has repeatable multi-step processes that involve agent calls, Frequency can orchestrate them.
Roadmap
- We're implementing cost tracking per step and the ability to set token budgets on agents / pipelines. We know roughly what we're spending but we want to attribute cost to individual pipeline stages.
- The dashboard is functional but we're still improving how it surfaces failure root causes.
- We are also close to enabling distributed execution. For our scale (10 pipelines, ~30 concurrent subjects) this hasn't been a bottleneck but it will be eventually.
- For complex workflows the generated config can get verbose. We're exploring a higher-level DSL but haven't committed to it.
Frequency vs other orchestrators
There's a wave of agent orchestration tools launching right now. Here's where Frequency sits relative to each category.
Temporal, Airflow, Conductor are general-purpose workflow engines for microservice orchestration with task queues, workers, and databases. Frequency is narrower: specifically for agent workflows where the primary operations are LLM calls and git operations, state is repo-local, and the execution model is poll-and-advance. Zero infrastructure overhead.
Symphony (OpenAI) polls Linear for issues, creates isolated workspaces per task, and runs a coding agent session for each. Frequency differs in two ways: it generates workflow config from your codebase rather than requiring an issue tracker, and it supports cross-pipeline coordination where multiple workflows are aware of each other. Symphony runs isolated sessions. Frequency runs coordinated pipelines.
Auto-Claude, Antfarm, and similar agent wrappers focus on making individual agent sessions more structured. Kanban boards, QA loops, spec-driven prompting. They're good at running one agent well. The gap we kept hitting across all of these are none of them coordinate multiple workflows with each other, often in parallel. In these wrappers, each session is isolated. We believe getting marketing to wait for deploy, or bug fixes to feed back through build, requires the kind of cross-pipeline coordination that Frequency was built around.
What's next
We're opening Frequency to design partners. If you want agents building and running your workflows autonomously, safely and at scale, sign up at our main page here at frequency.sh.
We're excited to see what you automate. We're working on additional workflows beyond app development and will share those results soon.
We also plan to periodically release further deep dives into the architecture and technicals as we open up the platform to all of you, so please follow our socials for further updates.